Seeing the operation of code in Atari 2600 games. This is a dual reprise of my dismap and mariosoup pieces that look at the code of cartridge games, and how the graphics are mixed in.
Tag Archives: code
Measuring Code Quality by WTFs/minute

via WTFs/m.
Just pulled an all-nighter pumping out some serious C code that, in theory, looked deceptively easy – but, in practice, was incredibly difficult to get my head around.
As a reward, here’s an oldie but a goodie – measuring code quality by WTFs/minute.
I’m sure whoever marks the code I just wrote will be WTF-ing very hard.
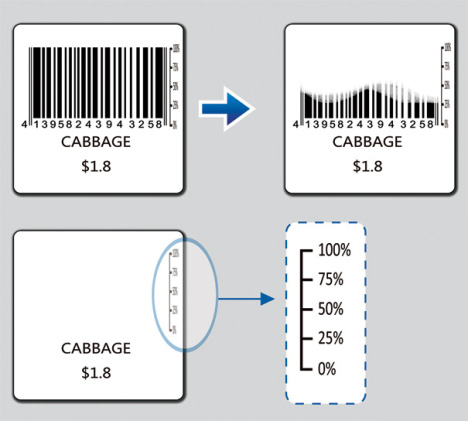
Fresh Code Ensures That You’ll Get Your Veggies Fresh
The Fresh Code is an intelligent barcode that doubles up as a graph, indicating the freshness of the vegetable that you’re checking out. The less fresh it is, the less the barcode is displayed, and when you don’t see a barcode, you’ll know that it’s not worth buying. It’s a cool concept, not to mention that when the barcode has disappeared, the cashier won’t be able to tag it to the point-of-sales machine, so they can’t really force you to buy old fruit or vegetables either. Neat huh?
This. Is. Awesome.
_oneliner is a self-reflexive installation consiting of a long line of interconnected VGA monitors, 64 in total. Each driven by a microcontroller, the monitors form a line of characters, like a giant ticker tape in which each monitor is limited to displaying a single character. The monitors are connected through self-designed and built “open” hardware. The work itself also reflects this openness: all wirings and microchips are exposed to the public’s critical inspection.
[…]
Every VGA monitor is capable of displaying a single character. Every monitor is run by a microcontroller which generates a VGA signal for a specific character. The Arduino is the controller of the installation: it continuously decides which monitor in the row displays which character, thus creating animations. There are 8 possible “programs” which can be run. The program number can be set using the 3 switches on the arduino shield, and pressing the reset button on the arduino. The LED then blinks as an indicator that it is running.

via _oneliner.
Click through the link to download technical documentation, including the source code, and other tasty tidbits.
Mission Impossible: The Code Even the CIA Can’t Crack
Almost 20 years after its dedication, the text has yet to be fully deciphered. A bleary-eyed global community of self-styled cryptanalysts—along with some of the agency’s own staffers—has seen three of its four sections solved, revealing evocative prose that only makes the puzzle more confusing. Still uncracked are the 97 characters of the fourth part (known as K4 in Kryptos-speak). And the longer the deadlock continues, the crazier people get.
[…]
The 97 characters of K4 remain impenetrable. They have become, as one would-be cracker calls it, the Everest of codes. Both Scheidt and Sanborn confirm that they intended the final segment to be the biggest challenge. There are endless theories about how to solve it. Is access to the sculpture required? Is the Morse code a clue? Every aspect of the project has come under electron-microscopic scrutiny, as thousands of people—hardcore cryptographers and amateur code breakers alike—have taken a whack at it. Some have gone off the deep end: A Michigan man abandoned his computer-software business to do construction so he’d have more time to work on it. Thirteen hundred members of a fanatical Yahoo group try to move the ball forward with everything from complex math to astrology. One typical Kryptos maniac is Randy Thompson, a 43-year-old physicist who has devoted three years to the problem. “I think I’m onto the solution,” he says. “It could happen tomorrow, or it could take the rest of my life.” Meanwhile, some of the seekers are getting tired. “I just want to see it solved,” says Elonka Dunin, a 50-year-old St. Louis game developer who runs a clearinghouse site for Kryptos information and gossip. “I want it off my plate.”

via Mission Impossible: The Code Even the CIA Can’t Crack.
Pfft. I bet the NSA could crack it in seconds. 😛
New theme, huh? Looks like [redacted].
So… Hopefully you’ve noticed the new theme by now.
If you haven’t, I have no idea what you’re doing here at this very second. You do realise that you’re on the internet, yeah? :S
I hated the old theme for a number of reasons –
- Horribly commented code.
One of my pet peeves has to be programmers (web or otherwise) who don’t follow good programming practices. In Satiorii’s case, it wasn’t just lack of comments – just a lack of readability in general. Ugh. - Sidebars at the BOTTOM of the page.
Uh, hello? Sidebars at the BOTTOM of the page? That’s just not cool – it might have been had you included links to jump down quickly, but in any case, sidebar widgets looked like they had been hacked together, and ugly as hell – misalignment, horrible formatting, etc.. 🙁 - No search.
See 2. Because search was so horrible, it wasn’t even worth using.
The previous theme – you could clearly tell it wasn’t designed to be modified. Plus it didn’t seem to be made by someone who understood how wordpress works – at least, not in the traditional blogging sense.
However, it wasn’t all bad – I chose to look past it’s shortcomings to focus on the good, because that’s the kind of guy I am. 😀
I did like elements of it, otherwise it wouldn’t have stayed as long as it did – particularly the awesome header links that showed off my pages:
 They’re quite nice – I love it how it placed those things front and centre, exactly where they should be.
They’re quite nice – I love it how it placed those things front and centre, exactly where they should be.
Another thing I quite liked was the awesome typography of the blog name and sub-heading – under OSX, it just looked awesome. However, under Windows it was a different story – it seemed to be borked for most people anyway (or maybe just Chris). Maybe it’s how the two OSs render fonts, or how the anti-aliasing was waaaaay nicer on OSX, or something.
Anyway, I hope you like the new theme. It’s (the somewhat popular) Grid Focus, by Derek of 5thirtyone.com – if you have a chance, head over to that site to check out more themes. I’m even thinking of using The Unstandard theme for the Radi8 website… Oops, probably shouldn’t have leaked that 😉